
Word2vec
1. CBOW & Skip-Gram
Skip-gram is an easier model, so we just discuss it only. Suppose that the size of vocabulary is 10000, and we want to map it into a 300-dim features vector. It’s consists of a hidden layer (10000x300) and an output layer(300x10000).
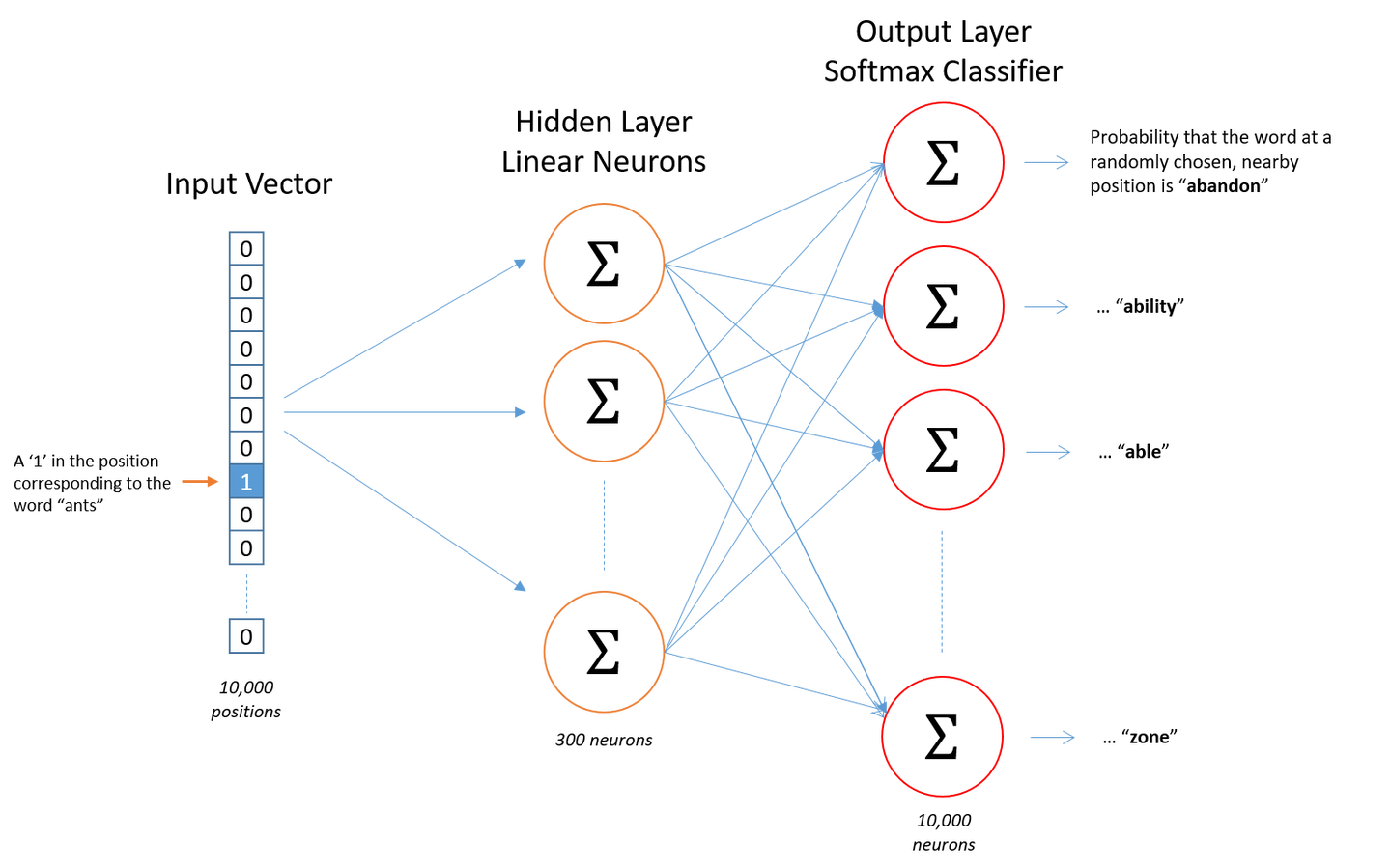
Note that there are millions of parameters that needs updating, so we have to use some strategies to avoid this.
Word Pairs
“New York” are regarded as single word, which has different meanings from “New” and “York”.
Subsampling Frequent Words
There are some words that apear very frequently in the sentences. For instance, “the” is a very common word, so there will be a lot of pairs like (…, “the”) which may provide little information about the meaning of the word.
For each word we encounter in our training text, there is a chance that we will effectively delete it from the text. The probability that we cut the word is related to the word’s frequency.
Negative Sampling
This methods only update part of the parameters which has less calculations. For example, we have a word pair (“fox”, “quick”). We’ll update the weights of positive word “quick” and other 5 (2-5 for small corpus, 5-20 for big corpus) random negative words from 10000. In this way, we just need to update 300*6 weights. Here we don’t talk about the details of how to choose the negative words.
https://zhuanlan.zhihu.com/p/27234078 http://mccormickml.com/2017/01/11/word2vec-tutorial-part-2-negative-sampling/
2. Character Embedding
Character Embedding has better performance while handling the OOV problem.
Character embedding models tend to do better than word embedding models for words that occur infrequently since the character n grams that are shared across words can still learn good embeddings. Word embedding models in contrast suffer from lack of enough training opportunity for infrequent words.