
Recurrent Neural Network
1. RNN
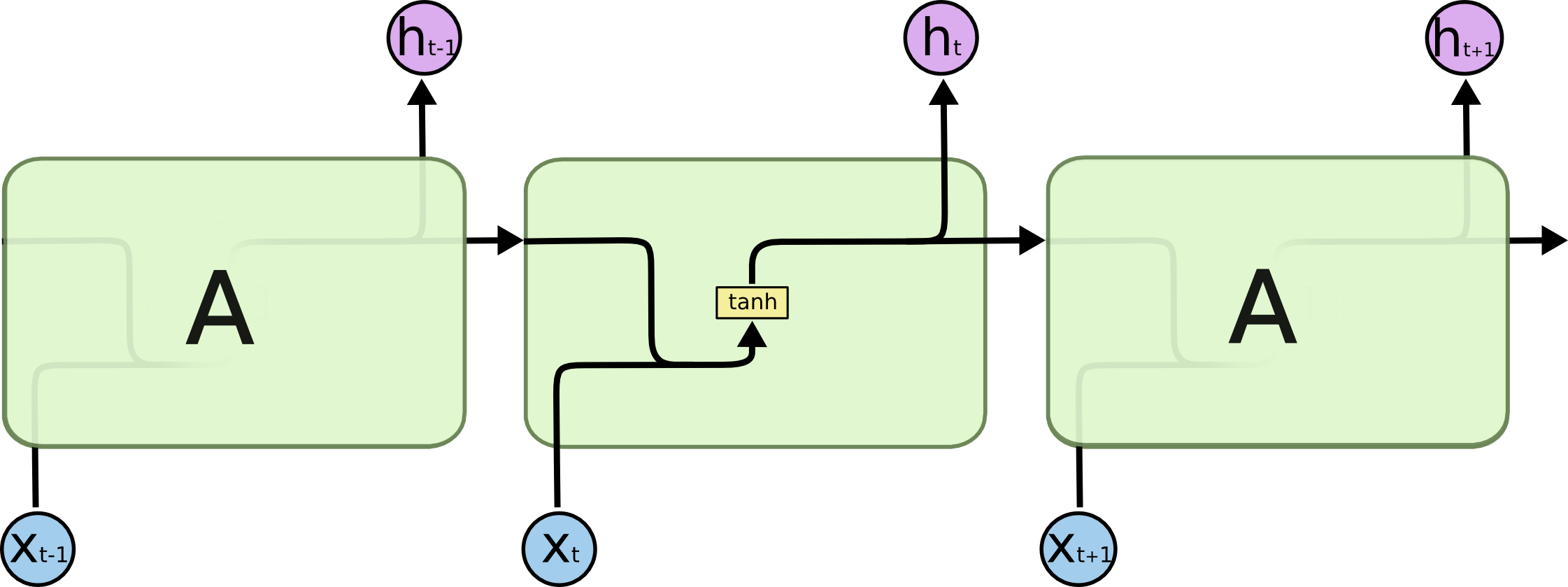
Hidden state at time t depends on the current input and the previous hidden state. Activation function’tanh’ add unlinearity and output values from -1 to 1.
$$h_t = \tanh(W_t \cdot [h_{t-1}, x_t]+b_t)$$
import torch
import torch.nn as nn
rnn = nn.RNN(input_size, hidden_size, num_layers)
input1 = torch.randn(sequence_length, batch_size, input_size)
h0 = torch.randn(num_layers*num_directions, batch_size, hidden_size)
output, hn = rnn(input1, h0)
RNN is useful in short sequence, but may encounter ‘gradients vanishing’ and ‘gradients explosion’ while processing long sequence.
2. Long Short Term Memory (LSTM)
LSTM has very similar structures of RNN. It’s consists of ‘forget gate’, ‘input gate’ and ‘output gate’.
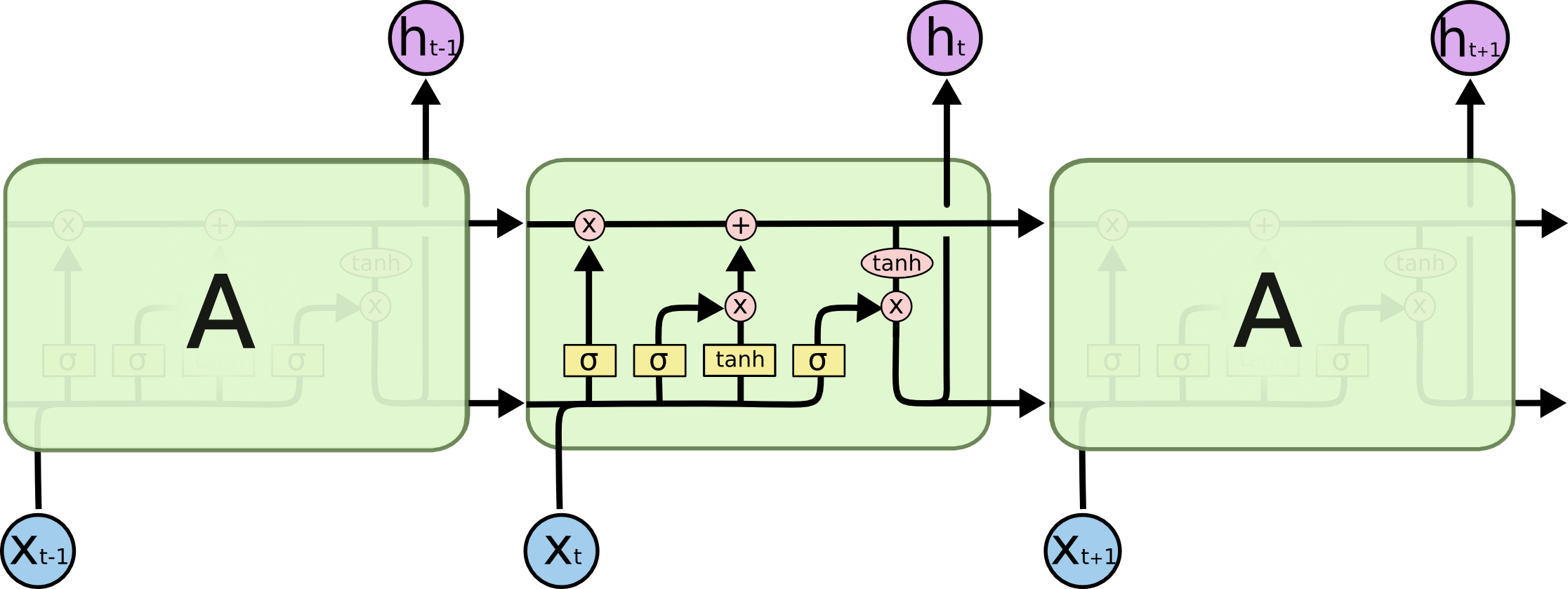
Forget Gate
$$f_t = \sigma(W_f \cdot [h_{t-1}, x_t]+b_f)$$
Input Gate
The $$\tilde{C}_t$$ denotes the inner states of the LSTM.
$$i_t = \sigma(W_i \cdot [h_{t-1}, x_t]+b_i)$$
$$\tilde{C}t = \tanh(W_C \cdot [h{t-1}, x_t] + b_C)$$
As for the update of the cell states,
$$C_t = f_tC_{t-1} + i_t\tilde{C}_t$$
Output Gate
$$o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o) \ h_t = o_t*\tanh(C_t)$$
import torch
import torch.nn as nn
lstm = nn.LSTM(input_size, hidden_size, num_layers)
input1 = torch.randn(sequence_length, batch_size, input_size)
h0 = torch.randn(num_layers*num_directions, batch_size, hidden_size)
c0 = torch.randn(num_layers*num_directions, batch_size, hidden_size)
output, (hn, cn) = lstm(input1, (h0, c0))
Bi-LSTM
Applying LSTM twice in two directions, then concatenate the results. This will double the training cost.
LSTM aims to sovle the problems in RNN and obatin better results in longer sequence. However, the training cost also increase.
Reference
http://colah.github.io/posts/2015-08-Understanding-LSTMs/s
3. Gated Recurrent Unit (GRU)
$$z_t = \sigma(W_z \cdot [h_{t-1}, x_t])$$
$$r_t = \sigma(W_r \cdot [h_{t-1}, x_t])$$
$$\tilde{h}t=\tanh(W \cdot [r_t*h{t-1}, x_t])$$
$$h_t = (1-z_t)h_{t-1} + z_t\tilde{h}_t$$
These are ‘reset gate’, ‘update gate’. Bi-GRU is similar.
In short, GRU performs better than LSTM with less coputation cost but it can’t totally sovle the ‘gradients vanishing’. Also, it can’t be trained in parallel.
4. Conlusion
RNN is just like a resturant. A sequence of customers wait in the queue to buy lunch. And the resturant will provide different foods for different customer. The ‘memory function’ of RNN is just like the menu.